几天前,全球最大的数据库软件公司 Oracle 发布了最新版的 Oracle Database 23ai ,集成了最新的 AI Vector Search(AI 向量搜索引擎),允许根据概念内容轻松搜索存储在任务关键型数据库中的文档、图像和关系数据,为企业数据和应用程序开发带来 AI 科技赋能。

在计算机数据库科技的历史长河中,有两个关键时刻,一个发生在1970年,另一个则在1977年。
前者源自IBM的一篇论文,研究员埃德加·考特(Edgar Frank Codd)在《ACM通讯》上发表了《大型共享数据库数据的关系模型》(A Relational Model of Data for Large Shared Data Banks),这标志着数据库界的一次革命。
那时,市场主要是层次模型和网状模型的数据库产品。IBM虽然在1973年启动了System R项目研究关系型数据库,但并未及时推出产品,因为当时IMS(一种层次型数据库)在市场上表现出色,而推出关系型数据库可能会影响IBM内部利益,加上IBM庞大官僚机构的决策相对缓慢。
另一个关键时刻是1977年,硅谷迎来了一场创业热潮。年仅32岁的Larry Ellison(拉里·埃里森)与Bob Miner和Ed Oates创立了软件开发实验室(Software Development Laboratories,SDL),这家公司后来成为ORACLE公司的前身。
Ellison当时只是一名普通的软件工程师,而公司的创立者中,Miner担任总裁,Oates为副总裁,Ellison则因为一份合同工作而未全职加入。他们开始尝试开发通用软件,直到Oates看到了埃德加·考特的著名论文并推荐给Ellison和Miner后,他们决定跟随IBM的脚步,策划构建可商用的关系型数据库管理系统(RDBMS)。
很快,他们开发出了一个初具雏形的产品,说是产品,其实更像是一个演示版本,起初被命名为ORACLE。据说这个名字取自字典中“神谕、预言”的意思,象征着智慧的源泉。
1979年,SDL更名为关系软件有限公司(Relational Software,Inc.,RSI),以突出公司核心产品。1983年,为了进一步突出产品,公司再次更名为ORACLE(Oracle Systems Corporation)。这个名字在未来成为了全球最大的数据库软件公司之一,成为了IT业界的传奇。

Oracle曾经被广泛视为关系型数据库的代名词,然而,随着各行各业数据采集、存储和使用需求的不断演变,人们对数据的需求也变得多样化。
文档和多媒体数据通常使用XML和JSON等格式进行存储,而图形数据库、空间数据库和键值存储则用于执行连接性分析、地理分析和高性能查找。
经过47年的发展,Oracle已经不再局限于处理结构化关系型数据,而是发展成为一个多模型数据库管理系统。
它不仅可以存储和处理多种结构化数据,还可以存储和处理多种非结构化数据。
Oracle可以根据特定负载需求提供所需的数据格式、访问方法、索引和编程语言支持,同时实现通用管理、安全策略以及事务和数据一致性。
它融合了内存列存储、分片数据库模型以及文档存储、空间数据库和图形数据库等功能。这种多模型方法可以简化跨多种数据格式的数据集成。

在Oracle中,管理这些数据模型的方法因数据的创建方式和使用方式而异。
它可以处理来自各种来源的海量数据,例如桌面办公系统中的文档、电子表格和演示文稿,以及专用工作站和设备中的地理空间分析系统和医疗捕获及分析系统中的数据。
此外,Oracle还可以处理政府、学术界和工业界的TB级档案和数字图书馆,生命科学和药物研究中的图像数据银行和图像数据库,公共部门、电信、公用事业和能源行业的地理空间数据仓库,以及零售、保险、医疗卫生、政府和公共安全系统中的业务或健康记录、位置和项目数据以及相关的音频、视频和图像信息。
最后,Oracle还广泛应用于社交网络、传感器分析、推荐系统、欺诈检测、学术、药物和情报研究及发现应用中的图形数据。
很早之前我就测试和了解了 Oracle 23c 的一些内容,但在这次正式发布的时候,Oracle 直接改成了 23ai 的尾标 ,抛弃了多年一直使用的c(Cloud)尾标,还是让我有点惊讶,这或许也与Oracle掌舵人 Larry Ellison(拉里·埃里森)狂傲的性格有关。

一直以来,Oracle都喜欢用超前的概念来命名自家产品。这次也不例外,他们将产品命名为 23ai,或许不仅仅是为了营销,更代表了传统数据库与当下最先进的AI技术相结合后的创新和探索。
这就像给一辆老爷车加装了火箭发动机,让人不禁感叹,Oracle 一直以来都在坚持以技术创新作为自己的核心竞争力,而这也是目前把市场营销和搞关系作为自己核心竞争力的国产数据库厂商们应该踏踏实实学习的地方。
结合Oracle的Blog,我来聊聊本次的 Oracle Database 23ai 版本中与AI 相关的新特性:
一、Augmenting a new generation of AI models(增强新一代 AI 模型)
1、 Oracle 23 AI Vector Search (Oracle AI 向量搜索)
我们知道,在12.2版本中,Oracle 就已经引入了向量优化技术,并在其后版本中一直在迭代改进。
其中,In-Memory深度矢量化是基于SIMD的框架,为查询计划中的高级查询运算符提供了矢量化支持。这一框架包含了SIMD、硬件加速和流水线执行等优化技术。
In-Memory矢量化连接是这一框架的核心特性。通过使用SIMD向量处理,该框架对哈希连接的各个方面(如哈希、构建、探测和收集)进行了优化。这种优化可以将联接处理的性能提高100%或更多。
In-Memory矢量化连接功能对用户是透明的,无需更改计划即可使用。默认情况下,当 INMEMORY_DEEP_VECTORIZATION 初始化参数为 true(默认值)时,将启用深度矢量化框架,可以通过将INMEMORY_DEEP_VECTORIZATION初始化参数设置为false来禁用这一优化。
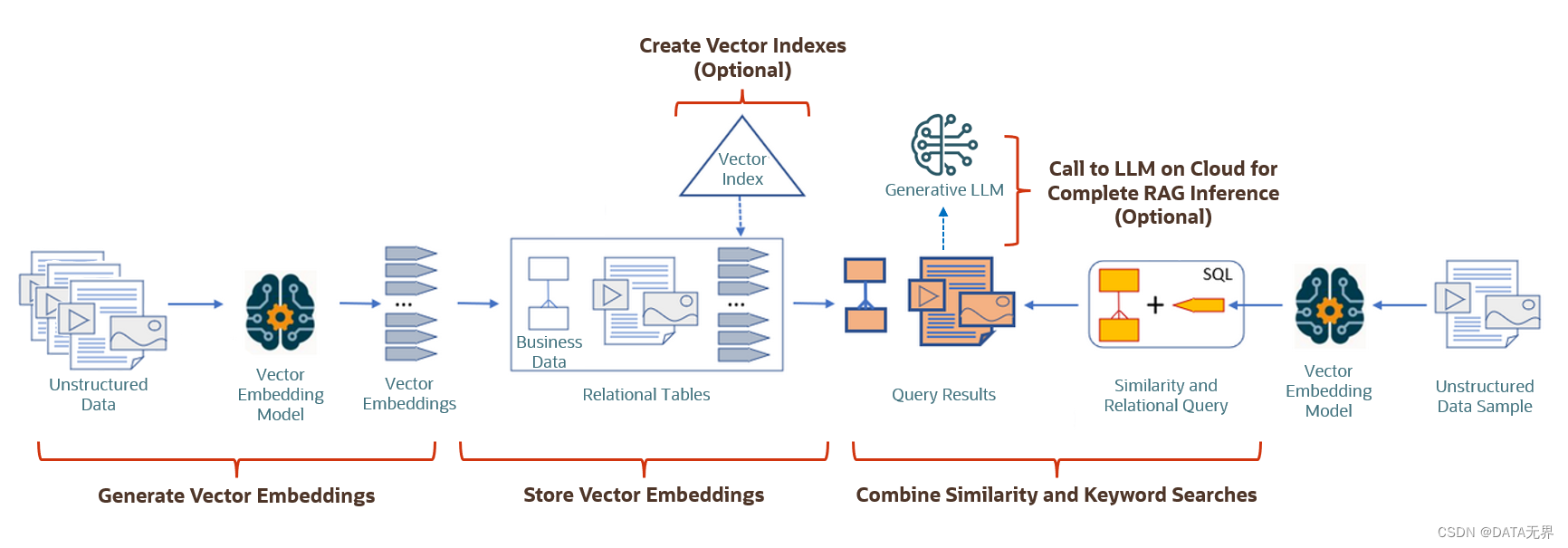
在Oracle 23ai 中, 向量优化功能进一步迭代升级至 AI Vector Search (AI 向量搜索),专为人工智能 (AI) 工作负载而设计,允许用户根据语义而不是关键字查询数据,这是一项强大的新技术,使您能够利用新一代 AI 模型来生成和存储向量。
这些向量(有时称为嵌入)是文档、图像、视频、声音等的多维表示。 通过将这些对象编码为向量,您可以获得使用数学计算查找它们之间的相似性的能力。
Oracle Database23ai 解决方案的真正强大之处在于,您可以使用简单的 SQL 将这些相似性搜索与业务数据搜索相结合。
任何对 SQL 有基本了解的人都可以创建一个强大的语句,将相似性和其他搜索条件结合起来。
这些类型的查询提供了LLMs额外的上下文,增强了他们的知识,使他们的回答更加准确,并与客户或组织的问题相关。
为了实现此功能,Oracle 向 SQL 语言添加了新的数据类型、新的向量索引和扩展,以便利用 Oracle Database 23ai 的高级分析功能,使查询向量与现有业务数据一起变得非常简单。
1)、新的数据类型(VECTOR)
Oracle Database 23ai 引入了新的 VECTOR 数据类型,为在数据库中存储向量嵌入和业务数据提供了基础。通过使用向量嵌入模型,用户可以将非结构化数据转换为向量嵌入,然后可用于对业务数据进行语义查询。
比如在创建新表时,可以使用以下 SQL 语句定义 VECTOR 数据类型字段
CREATE TABLE docs (INT doc_id, CLOB doc_text, VECTOR doc_vector);
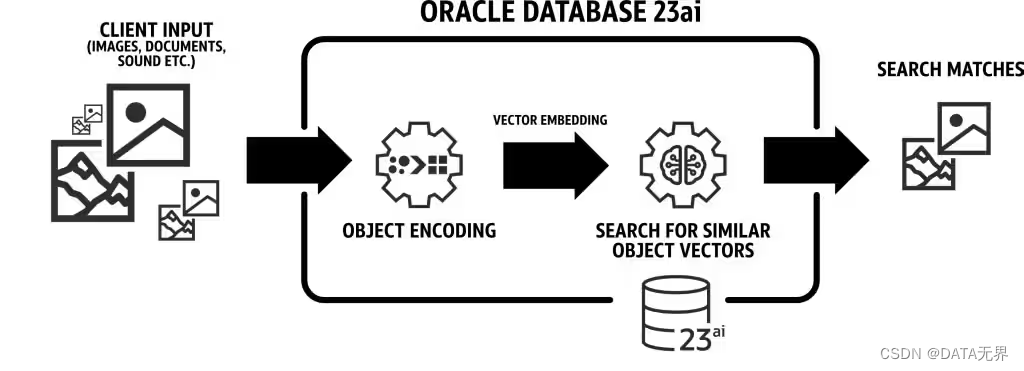
Oracle AI Vector Search 存储向量嵌入,它们是数据点的数学向量表示。这些向量嵌入描述了单词、文档、音轨或图像等内容背后的语义。例如,在进行基于文本的搜索时,向量搜索通常被认为比关键字搜索更好,因为向量搜索是基于单词背后的含义和上下文情境来理解搜索的含义,而不是实际单词组成的字符本身。
这种向量表示会将人类所感知的对象的语义相似性转换为数学向量空间中的接近度表示。而数学向量空间通常具有数百甚至数千个维度。
换句话说,向量嵌入是一种可以将几乎任何类型的数据(例如文本、图像、视频、用户或音乐)表示为多维空间中的点的方式,其中这些点在空间中的位置以及与其他点的接近程度在人类语言学上是存在意义的。
下面这个简化的图展示了一个向量空间,其中每个单词都被被编码为一个二维向量。
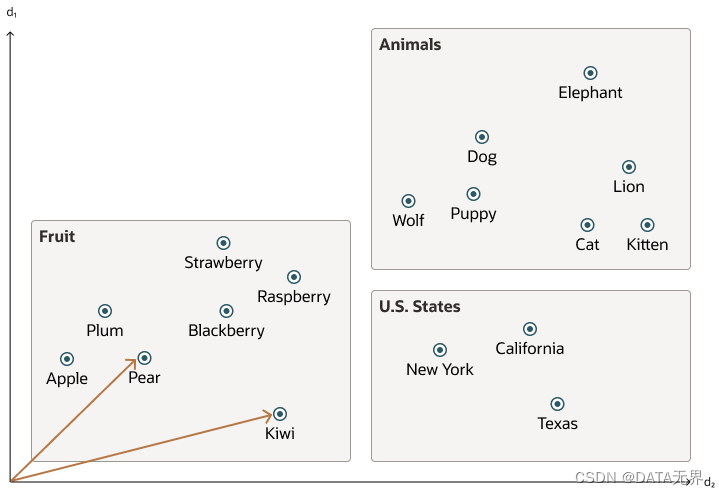
而搜索数据集中的语义相似性就像在一个向量空间中寻找最接近的邻居一样,而不是使用传统的关键字搜索。
在下面这个向量空间中,我们可以发现,狗和狼之间的距离比狗和小猫之间的距离短。
换句话说,在这个向量空间里可以看出,狗和狼的相似度超过了狗和小猫。
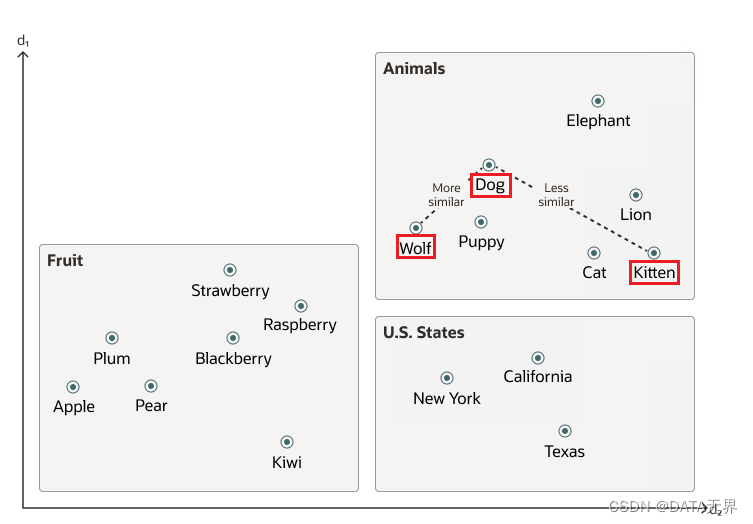
向量数据的分布通常是不均匀的,并且会聚集成一些具有语义关联性的组合。
进行相似性搜索时,我们要做的就是在向量空间中查找与给定查询的单词向量最接近的 K 个向量。
简单来说,我们需要对这些向量进行排序,以便找到一个有序列表,其中第一行是与查询向量最相似的向量,第二行是与查询向量次相似的向量,以此类推。
在进行向量相似性搜索时,重要的是相对距离的顺序,而不是实际距离的大小。
在下面这个例子中,我们使用向量空间进行语义搜索。
假设我们查询的向量是代表单词“Puppy”的向量,我们想要找到与之最接近的四个单词:

当我们进行相似性搜索时,比如查找与某个问题或查询向量最相似的内容,通常会根据查询向量的数值和大小从一个或多个聚类(类似于一组相似的数据)中获取数据。这就像是在一堆相似的东西中找出与你手头问题最相似的那个。
使用向量索引进行近似搜索就像是在这些聚类中建立了一个索引,这样我们可以更快地找到可能与查询向量最相似的那些内容。
而精确搜索则需要逐个查看所有聚类,这就像是不借助索引,一个个地查找可能符合条件的内容,效率就会比较低。
2)、新的向量索引(Vector Indexes)
向量索引是在向量嵌入上创建的一类专门的索引数据结构,旨在使用高维向量在巨大的向量空间上加速相似性搜索。
向量索引使用聚类、分区和邻居图等技术对表示相似项的向量进行分组,这大大减少了搜索空间,从而使搜索过程极其高效。
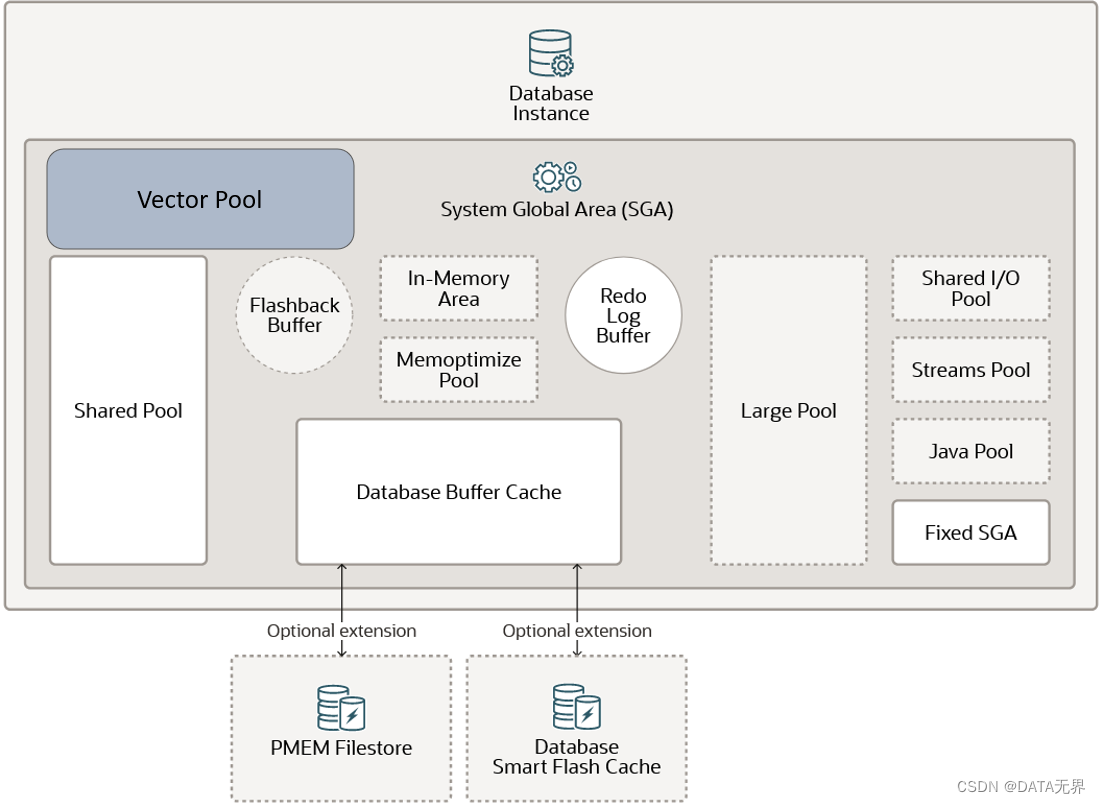
从 Oracle 23ai 版本的内存体系架构上看,Oracle 为向量搜索引入了一个新的被称为 Vector Pool(向量池)的内存结构。要允许创建向量索引,必须在系统内存中启用 Vector Pool(向量池)区域,并设置 VECTOR_MEMORY_SIZE 初始化参数分配向量池的大小。
这个内存区域同样位于SGA(系统全局区)中,用于存储 “Hierarchical Navigable Small World (HNSW) ” 向量索引和所有相关元数据。它还用于加速反向平面文件 (IVF) 索引的创建以及对具有 IVF 索引的基表的 DML 操作。
“Hierarchical Navigable Small World (HNSW) vector indexes” 是一种用于高效存储和检索向量数据的技术。它是一种索引结构,旨在快速搜索高维向量空间中的相似向量。
这个名字中的几个关键词可以帮助理解它的作用:
- “Hierarchical” 表示这种索引结构是分层的,可以加快搜索速度。
- “Navigable” 表示这种结构可以帮助在向量空间中导航,快速找到目标向量。
- “Small World” 意味着这种结构可以在高维空间中创建一个小世界网络,使得相似的向量彼此之间更容易访问。
HNSW vector indexes 特别适用于需要在高维向量空间中进行相似性搜索的场景,如文本搜索、推荐系统等。
从文档来看,Oracle AI Vector Search 支持以下类别的基于近似最近邻 (ANN) 搜索的向量索引方法:
- In-Memory Neighbor Graph Vector Index(内存中邻居图向量索引)
- Neighbor Partition Vector Index(邻居分区向量索引)
2、Secure encoding of data(数据的安全编码)
要实现大语言模型 LLMs 提供的显著好处,我们首先需要充分了解数据集和其中的对象。
大语言模型对这些数据对象进行编码可能需要大量且复杂的代码。因此,将这种数据转移到数据库之外的第三方服务去处理是目前的常见做法。
但是这可能需要用户与第三方服务提供商共享客户的敏感数据和信息,并在数据的安全存储、传输、访问过程中承担一定的责任和风险。
为了确保数据集和对象的安全编码,Oracle Database 23ai 允许用户直接加载自己可信的 AI 大模型到数据库中,通过支持 ONNX 标准。这使得 Oracle Database 23ai 能够在将对象插入数据库时对其进行编码。这样可以安全地近乎实时地对对象进行推理,并确保无需从数据库中提取敏感数据并将其移交给第三方服务。
3、Asking questions naturally(使用自然语言提问)
当您想要从数据库中获取信息时,通常需要使用 SQL(Structured Query Language)这种专门的语言来编写查询。
虽然 SQL 是非常强大和灵活的,但对于初学者来说,学习它可能会有一些挑战。为了让更多的用户能够方便地提出复杂的问题,Oracle 正在与一些先进的语言模型(LLMs)如 Cohere 和 Llama 集成。
这种集成的目标是让用户可以用自然语言提出问题,而不必深入学习 SQL 的语法和细节。 举个例子,您可以简单地问:“展示过去 4 个季度受年轻一代欢迎的产品的销售情况”。
Oracle Database 23ai 将会解析这个问题,理解其中关键词的含义,然后将其转换为对数据库的实际查询。这样,您就可以通过自然语言与数据库进行交互,而不必亲自编写复杂的 SQL 查询语句。

这种方法的优势在于它使得数据库更加易于访问和理解,不仅可以用于提取数据,还可以用于了解数据库中各个方面的情况。这种集成使得利用数据库中的信息变得更加直观和高效,即使您不是专业的数据库管理员或 SQL 开发人员也能够轻松地获取所需信息。
4、Finding new insights in data(在数据中发现新见解)
自从 20 多年前发布了 Oracle Database 9iR2,该数据库就一直采用内置的机器学习(ML)算法。这些算法使用户能够快速地发现数据表中的模式和趋势,并预测客户行为。使用这些 ML 算法,用户可以进行复杂的机器学习操作,而无需进行复杂的 ETL(抽取、转换、加载)操作来提取数据并写回结果。
当数据被插入或加载到 Oracle 数据库时,这些模型可以用于分类、聚类和预测,从而为用户提供实际的业务优势,例如客户建议和欺诈检测。自从这个版本发布以来,Oracle 一直在不断改进数据库,并为其添加新的 ML 算法和功能,使其成为业界最复杂、功能最强大的数据挖掘平台之一。
5、Available in all editions of the Oracle Database(在 Oracle 数据库的所有版本中均可用)
AI Vector Search 是 Oracle Database 23ai 的一部分,在企业版、标准版 2、Database Free 和所有 Oracle 数据库云服务中均免费提供。
综合来看,仅仅在与AI 相关的新特性中,Oracle Database 23ai 提供的新功能和特性已经非常强大。
Oracle Database 23ai 的 AI 矢量搜索非常简单易用,它通过向现有的关系数据库系统添加向量列来实现。
这意味着用户可以将向量数据与企业已有数据存储在同一记录中,然后可以使用单个 SQL 查询语句对它们进行相似性排序。
这种设计使得将大型语言模型与公司数据结合起来,创建和运行企业级检索增强生成(RAG) 系统变得非常容易。
另一个很棒的功能是,Oracle Database 23ai 支持使用 SQL 进行矢量检索。这对于处理矢量数据的工程师来说是非常方便的。
此外,管理 AI 数据也非常便捷,无需额外费用。 这些特性使得 Oracle Database 23ai 成为当今世界许多行业大中型企业数据库客户的首选。
此次Oracle Database 23ai 一经发布,便在数据库行业内引起一波讨论的热潮,而之前天天宣传营销,言必称各种跑分刷榜第一、吊打 Oracle 的各类国产数据库们纷纷沉默不语了。
根据工信部数据库发展白皮书2022的报告,截至2022年6月底,国内已经涌现出116家国产数据库厂商,预计到了当下的2024年,这一数字已经超过了200家。
相比十多年前寥寥无几的情况,国产数据库产业近年来的发展速度确实惊人,可以说是在大形势下迎来了蓬勃发展的新机遇。
在这些新兴的国产数据库厂商中,存在着一些认真研发和投入巨资,真心从事数据库产业的企业,但在竞争激烈、野蛮生长的当前环境下,也不乏有一些鱼目混珠、欺世盗名的水货公司。
在今年4月26日,十四届全国人大常委会举行的第十讲专题讲座上,中国工程院院士、中国科学院计算技术研究所研究员孙凝晖在《人工智能与智能计算的发展》的讲座中提到:
十四届全国人大常委会专题讲座第十讲讲稿:人工智能与智能计算的发展
英伟达CUDA⑤(Compute Unified Device Architecture, 通用计算设备架构)生态完备,已形成了事实上的垄断。国内生态孱弱,具体表现在:
一 是研发人员不足,英伟达CUDA生态有近2万人开发,是国内所有智能芯片公司人员总和的20倍;
二 是开发工具不足,CUDA有550个SDK(Software Development Kit, 软件开发工具包),是国内相关企业的上百倍;
三 是资金投入不足,英伟达每年投入50亿美元,是国内相关公司的几十倍;
四 是AI开发框架TensorFlow占据工业类市场,PyTorch占据研究类市场,百度飞桨等国产AI开发框架的开发人员只有国外框架的1/10。
更为严重的是国内企业之间山头林立,无法形成合力,从智能应用、开发框架、系统软件、智能芯片,虽然每层都有相关产品,但各层之间没有深度适配,无法形成一个有竞争力的技术体系。
国产数据库在这一点上可以说和当前国内的AI大模型产业领域极其相似。
由于起步较晚,国产数据库产业的人才储备和资金投入都相对非常有限,这导致产业内部碎片化严重。
国内真正有实力做数据库内核研发的人才极其有限,超过60%的数据库厂商员工规模不到100个人,而超过500个人的企业不到10%。
而对于大多数参与国产数据库行业的玩家和背后的投资方来说,可能没有什么比尽快拿出产品、尽快推动销售、尽快实现盈利更强烈的动机了,因此95%以上的国产数据库公司几乎都是从国外开源的 MySQL 和 PostgreSQL 数据库分支出来,拿着开源代码搞搞外围研发和XC适配功能的实现,就可以申报政府补贴和开展销售了,并美名其曰 “国产自研,可控可信”。
对于那些希望自己成为IT基础设施领域皇冠——数据库行业领军者的中国数据库企业来说,最大的企业规模可能还不如某些二三流国外数据库厂商的一个小的研发部门,更别说和当今世界最大的数据库软件公司 Oracle 这种巨无霸和行业领头羊超过2万人的研发部门和更为庞大的研发支持体系和每年投入的巨额研发资金相比了。
而国内像涛思数据的创始人陶建辉老师那样不依赖任何开源或第三方软件,从零开始造轮子,独立开发拥有自主知识产权并且开源的 TDengine 时序数据库的创业者,真的是屈指可数,到目前为止,TDengine 已经在 GitHub 上获得 22.8k Star,这样逐渐在全球开枝散叶的产品,才真正代表了国产数据库的科技创新与未来。

实际上在我看来,目前的国产数据库行业只是一种表面的繁荣,而内里却暗藏危机。
随着目前国内数据库市场竞争的进一步加剧,在营销宣传和项目招标中已经出现利用一些指定的参数,通过不上台面的手段排除竞争对手、党同伐异、互相攻击的行业乱象,长久以往,对于本就技术薄弱的中国数据库产业的长远发展会带来非常大负面影响,无法形成一个有竞争力的技术生态和体系。
一方面,这种激烈的竞争促使企业不断提高自身实力和竞争力,推动了整个行业的发展。
另一方面,竞争过度可能导致山头林立、资源浪费、产品同质化等问题,对行业的长远发展造成隐患。
目前,我们难以断定这种局面对中国数据库产业发展究竟是的有利还是不利,但这种竞争激烈的局面无疑为产业的未来发展带来了诸多未知因素。